
断点续传与个人网盘系统的前后端设计
功能设计
- 登录鉴权:进入系统必须先登录,未登录无法访问到后端接口与网盘的静态资源
- 上传:断点续传、文件秒传
- 文件分享:生成一个随机密钥字符串与一个资源访问地址,输入密钥验证成功即可访问到该资源,密钥会在一定时间内过期
- 回收站:删除后的文件默认先保留在回收站,7 天后自动删除
- 文件操作: 新建文件夹、重命名、移动、删除、批量删除
技术选型
- 前端:使用 Vue 构建,使用 ElementUI 构建 UI,使用 vue-simple-uploader 插件实现上传的断点续传、文件秒传功能。
- 后端:使用 Koa 实现,直接使用 Koa 搭建静态资源服务器(即个人网盘资源目录),加入静态资源鉴权,使用原生 Nodejs 处理文件管理与上传功能。
问题与思考
Q:是否需要使用数据库,将文件信息保存到数据库中?
原则上,文件的增删查改都将使用原生 nodejs 进行操作,这些都不需要使用到数据库。但是原生 nodejs 并不能直接读取到文件的 MD5 值,在断点续传与秒传功能中就无法通过传来的 MD5 标识跟本地的文件进行匹配。所以还是需要建立一个含文件 MD5、文件路径等信息的数据表记录本地文件的 MD5。
Q:若使用了数据库记录文件 MD5 信息,怎么保证数据表的数据与本地物理存储是同步的?
如果进行文件操作并不是通过该文件管理系统,而是直接在 windows 上进入到网盘目录进行文件增删改,这时我们的应用是无法监听到文件的变更的,数据表数据并不会更新。这样就会出现我把某个文件删除了,但是数据表仍然记录了该文件是已经上传的情况。
原本是想采用使用定时器定时对本地文件与数据表进行数据同步,但是发现这样在后期文件多或嵌套深的情况下性能会很差,这种方式并不合适。
由于这些信息只是在文件断点续传与秒传功能中需要用到,后面采用的方案为:直接在预探请求中先判断数据库信息是否与本地物理存储相符,如果不相符则认为本地已不存在,需要重新上传。(原则上是不推荐直接使用 windows 进入目录进行文件操作,而是都通过这个文件管理系统进行文件操作)
Q: 同一个文件,但存在于网盘不同目录下,同时在不同目录删除该文件,回收站中是否会冲突?
删除文件时,使用原文件名+时间(yyyy-MM-dd HH:mm:ss)进行重命名后再移动文件到回收站。同时需要往数据库记录文件删除的信息,删除前的文件路径与删除时间等,以便实现文件还原与回收站定时清理的功能。
Q:文件夹并无 MD5 值,删除文件夹如何确保可以还原?
删除文件夹与删除文件属于同样的操作,也是通过文件夹名+时间重命名后移动到回收站目录。但是数据库中需要使用一个新的数据表记录文件夹的删除信息。
实现
文件鉴权
登录时保留 session, 然后使用一个中间件鉴权,如果没有 session 则不允许访问系统除登录接口外的其他任何请求,包括静态资源。使用 koa-static 构建静态资源服务器,并将 defer 属性设置为 true,让它允许通过鉴权中间件。
// ...
app.use(async (ctx, next) => {
if (ctx.url.includes("/storage") && ctx.url !== "/storage/login") {
if (!ctx.session.isLogin) {
ctx.body = r.loginError();
return;
}
}
await next();
});
// ...
app.use(
static(__dirname + "/public", {
defer: true,
})
);
// ...
const router = new Router({
prefix: "/storage",
});
// ...
router.post("/login", async (ctx) => {
const { access } = ctx.request.body;
if (!access) {
ctx.body = r.parameterError();
return;
}
try {
const base64Decode = new Buffer.from(access, "base64");
const genAccess = base64Decode.toString();
if (storageRootKey !== genAccess) {
ctx.body = r.error(311, "密码错误");
return;
}
ctx.session.isLogin = true;
logger("登入Storage");
ctx.body = r.success();
} catch (e) {
ctx.body = r.error(310, "登录失败");
}
});这里设置的文件系统接口为 storage/*,静态资源服务器为 public/storage,登录时前后端会把密码进行简单 base64 转码。
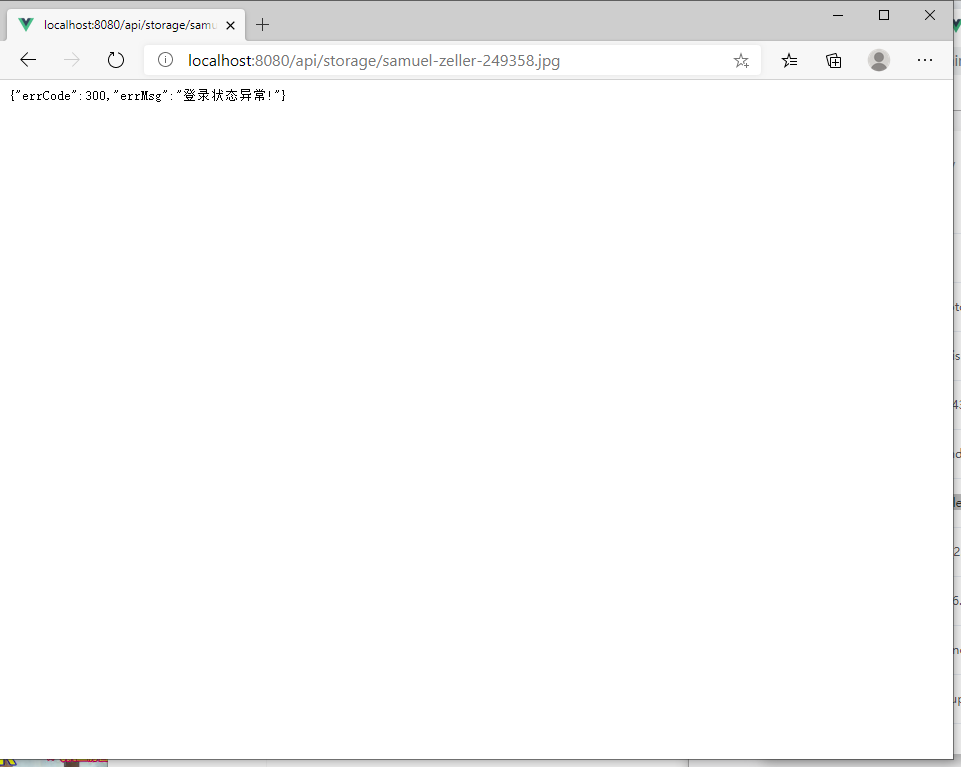
若未登录直接访问静态资源,则回返回错误信息。
未登录直接访问
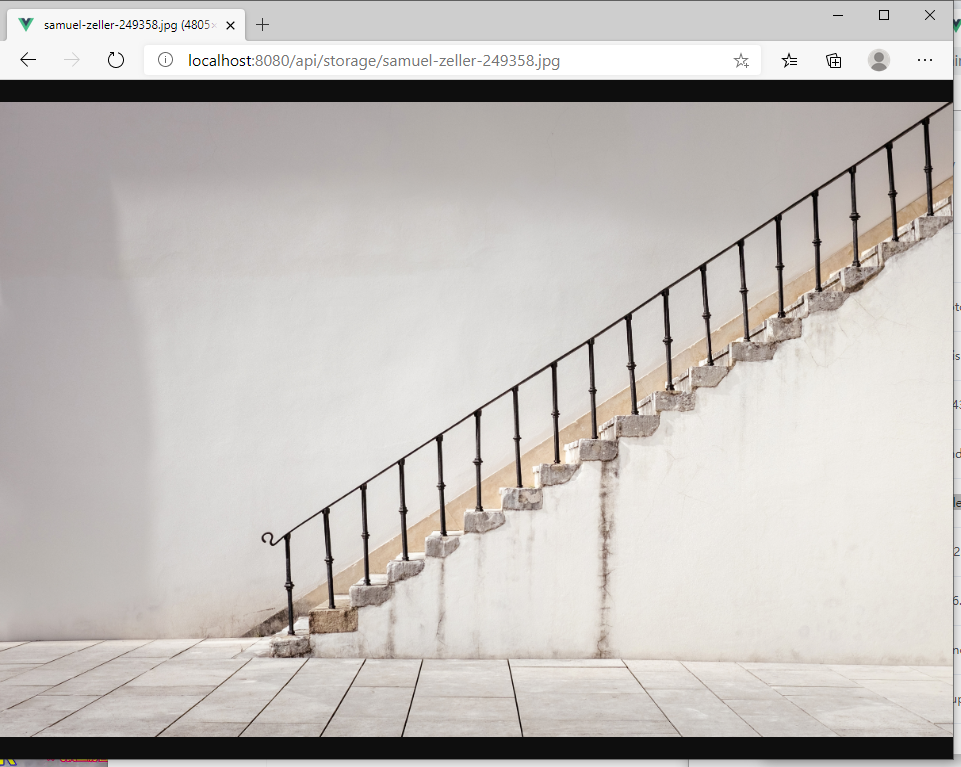
登录后在访问
断点续传与文件秒传
文件 md5 计算
实现断点续传与文件秒传的前提是需要确定出文件的唯一标识,最好的方式是计算出文件的 md5 值。
由于选择的 vue-simple-uploader 没有直接提供文件 md5 计算的 api,因此需要手动实现。这里采用 spark-md5 插件计算文件的 md5,在 file-added 事件中,直接用 fileReader 读取文件,根据每个切片循环算出 md5。
注意尽量不要直接一次读取整个文件的 md5,直接读取大文件在 IE 浏览器中有可能会出现卡死的情况,遍历读取每个切片可以减轻浏览器计算压力。
methods: {
hanldeFileAdd (file) {
const fileList = this.$refs.uploader.files
const index = fileList.findIndex(item => item.name === file.name)
if (~index) {
file.removeFile(file)
} else {
file.targetPath = this.currentPath
this.computeMD5(file)
}
},
computeMD5 (file) {
const fileReader = new FileReader()
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice
let currentChunk = 0
const chunkSize = CHUNK_SIZE
const chunks = Math.ceil(file.size / chunkSize)
const spark = new SparkMD5.ArrayBuffer()
this.$nextTick(() => {
this.createMD5Element(file)
})
loadNext()
fileReader.onload = e => {
spark.append(e.target.result)
if (currentChunk < chunks) {
currentChunk++
loadNext()
this.$nextTick(() => {
this.setMD5ElementText(file, `校验MD5 ${((currentChunk / chunks) * 100).toFixed(0)}%`)
document.querySelector(`.uploader-list .file-${file.id} .uploader-file-actions`).style.display = 'none'
})
} else {
const md5 = spark.end()
file.uniqueIdentifier = md5
file.resume()
this.destoryMD5Element(file)
document.querySelector(`.uploader-list .file-${file.id} .uploader-file-actions`).style.display = 'block'
}
}
fileReader.onerror = function () {
this.$nextTick(() => {
this.setMD5ElementText(file, '校验MD5失败')
})
file.cancel()
}
function loadNext () {
const start = currentChunk * chunkSize
const end = ((start + chunkSize) >= file.size) ? file.size : start + chunkSize
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end))
}
},
createMD5Element (file) {
this.$nextTick(() => {
const el = document.querySelector(`.uploader-list .file-${file.id} .uploader-file-status`)
const MD5Status = document.createElement('div')
MD5Status.setAttribute('class', 'md5-status')
el.appendChild(MD5Status)
})
},
destoryMD5Element (file) {
this.$nextTick(() => {
const el = document.querySelector(`.uploader-list .file-${file.id} .uploader-file-status .md5-status`)
if (el) {
el.parentNode.removeChild(el)
}
})
},
setMD5ElementText (file, text) {
const el = document.querySelector(`.uploader-list .file-${file.id} .uploader-file-status .md5-status`)
if (el) {
el.innerText = text
}
}
}将计算完的 MD5 直接替换到 file 对象的 uniqueIdentifier 属性上,最终发送的请求中的 identifier 将是文件的 MD5,后端通过该字段进行识别。
Vue-simple-uploader 文件列表状态需要加入计算 MD5 相关状态,可以通过 css 为原文件列表增加多一层 md5 状态层,然后通过相关事件进行显隐。
断点续传
默认 Vue-simple-uploader 提供了文件上传时的暂停/开始操作,你可以在上传过程中随时暂停。但是这个并不是真正的断点续传,因为页面刷新后,上传状态并没有保存下来,仍会重新从第一片重新上传。若将状态保留到 localstorage 中,仍是不太现实的,最好的方式是由后端返回是否需要当前这个切片,因为后端能知道当前该文件已上传的切片。
testChunks 属性设为 true(默认)时,每个切片会先发送一个不含文件流的预探 get 请求给后端,通过后端返回的 http 状态码(可更改)判断该切片是否需要发送。
默认每个切片都会发送一个预探请求,这样假如一个 10 个切片的文件就会产生 20 个请求,造成浪费。最理想的情况是预探请求只发送一个。新版 simple-uplder 也考虑到这点,并提供了 checkChunkUploadedByResponse 属性,可以将预探请求设置为一个,后端为这个预探请求直接返回当前已经有的切片数组,然后前端直接判断切片请求是否需要发送。
例:文件上传到一半,点了暂停,然后刷新网页,再重新上传。文件校验完 Md5 后,预探请求返回已存在的切片数组[1~25],然后真正切片请求会直接从第 26 片开始上传。
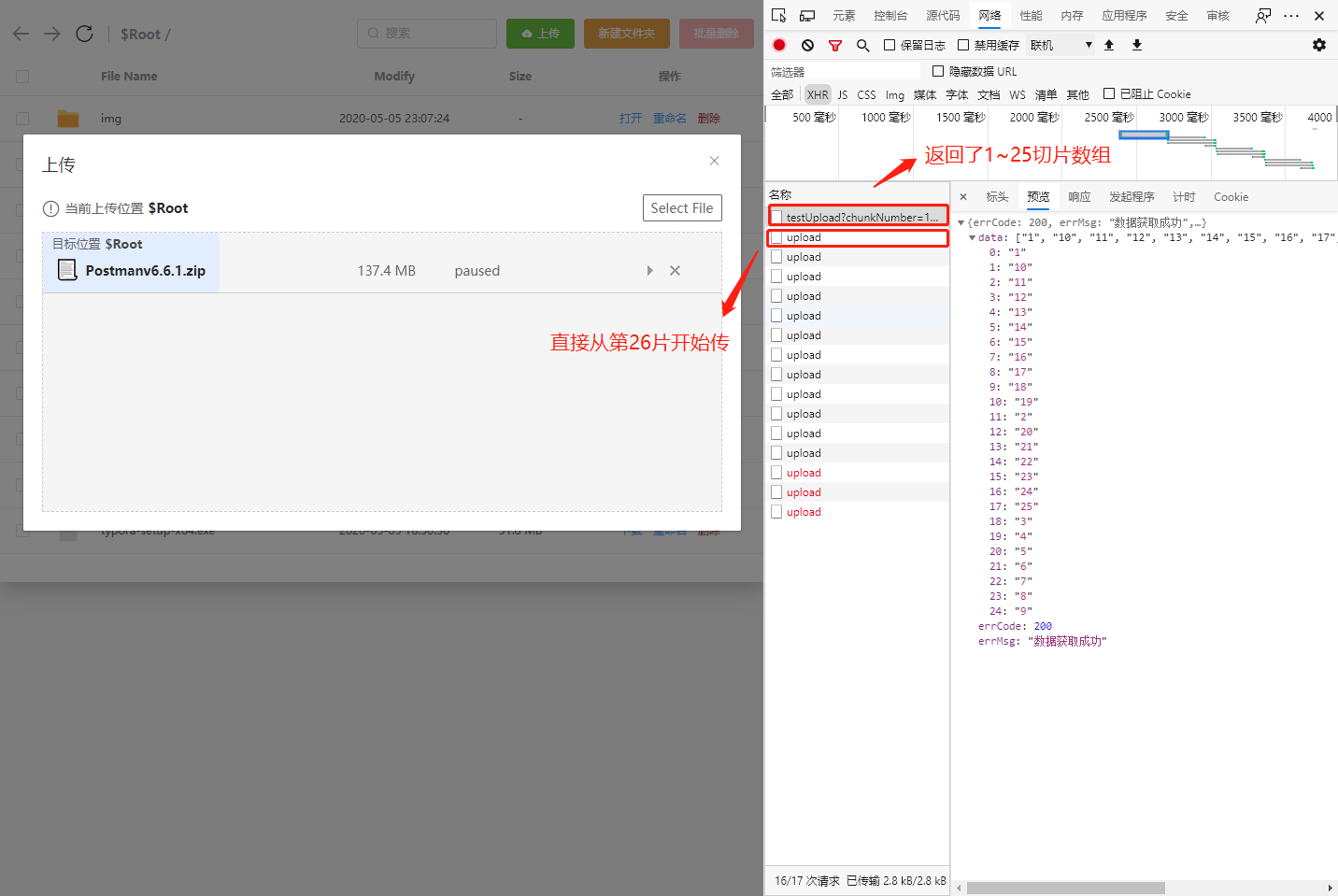
前端处理
// 前端vue-simple-uploader配置项
options: {
target: (instance, chunk, isTest) => isTest ? '/api/storage/testUpload' : '/api/storage/upload',
query: () => {
return {
targetPath: this.currentPath
}
},
chunkSize: CHUNK_SIZE,
allowDuplicateUploads: false,
checkChunkUploadedByResponse: (chunk, message) => {
const response = JSON.parse(message)
const existChunk = response.data.map(item => ~~item)
return existChunk.includes(chunk.offset + 1)
}
}其中/storage/testUpload 为预探请求(get),storage/upload 为真正切片上传请求(post)。checkChunkUploadedByResponse 控制只上传后端不存在的切片。
后端处理
router.get("/testUpload", async (ctx) => {
const { identifier, filename, targetPath = "$Root", totalChunks } = ctx.query;
const chunkFolderURL = `${storageChunkPath}/${identifier}`;
try {
const checkExistResult = await query(
`select * from storage where id = ? and isComplete = 1 and isDel = 0`,
identifier
);
// 检查是否已经完整上传过该文件
if (checkExistResult.length > 0) {
let { fullPath } = checkExistResult[0];
let realPath = fullPath.replace("$Root", storageRootPath);
// 检查当前DB信息是否与物理存储相符
if (fs.existsSync(realPath)) {
// 检查目标位置是否与之前上传的位置一样,不一致则复制过去
let targetFilePath = `${targetPath}/${filename}`;
if (fullPath !== targetFilePath) {
targetFilePath = targetFilePath.replace("$Root", storageRootPath);
fs.copyFileSync(realPath, targetFilePath);
}
// 返回全部分片数组
const chunksArr = Array.from(
{ length: totalChunks },
(item, index) => index + 1
);
ctx.body = r.successData(chunksArr);
return;
}
}
if (!fs.existsSync(chunkFolderURL)) {
fs.mkdirSync(chunkFolderURL, { recursive: true });
const now = DateFormat(new Date(), "yyyy-MM-dd HH:mm:ss");
const sql = `replace into storage(id, fullPath, updatedTime, isComplete, isDel) values(?, ?, ?, 0, 0)`;
await query(sql, [identifier, `${targetPath}/${filename}`, now]);
ctx.body = r.successData([]);
} else {
const ls = fs.readdirSync(chunkFolderURL);
ctx.body = r.successData(ls);
}
} catch (e) {
ctx.status = 501;
ctx.body = r.error(306, e);
}
});
router.post("/upload", async (ctx) => {
const {
chunkNumber,
identifier,
filename,
totalChunks,
targetPath = "$Root",
} = ctx.request.body;
const { file } = ctx.request.files;
const chunkFolderURL = `./public/storage-chunk/${identifier}`;
const chunkFileURL = `${chunkFolderURL}/${chunkNumber}`;
if (chunkNumber !== totalChunks) {
const reader = fs.createReadStream(file.path);
const upStream = fs.createWriteStream(chunkFileURL);
reader.pipe(upStream);
ctx.body = r.success();
} else {
const targetFile = `${targetPath}/${filename}`.replace(
"$Root",
storageRootPath
);
fs.writeFileSync(targetFile, "");
try {
for (let i = 1; i <= totalChunks; i++) {
const url = i == totalChunks ? file.path : `${chunkFolderURL}/${i}`;
const buffer = fs.readFileSync(url);
fs.appendFileSync(targetFile, buffer);
}
const now = DateFormat(new Date(), "yyyy-MM-dd HH:mm:ss");
const sql = `update storage set isComplete = 1, updatedTime = ? where id = ?`;
await query(sql, [now, identifier]);
ctx.body = r.success();
deleteFolder(chunkFolderURL);
logger(
"文件上传成功",
1,
`targetFile: ${targetFile}, MD5:${identifier}, 切片源删除成功`
);
} catch (e) {
ctx.status = 501;
ctx.body = r.error(501, e);
logger("文件合并失败", 0, `分片丢失 => ${e}`);
fs.unlinkSync(targetFile);
}
}
});在 testUpload 请求中,通过数据库与本地切片生成已存在的切片数组给前端,若从未传过还需要更新数据库记录。
在 upload 请求中,对每个切片使用 nodejs 管道流进行读写,将文件保留在 chunk 文件夹中,并以 md5 值为文件名,存放目标文件的切片。当遇到最后一个切片时,执行合并文件操作(需要注意,最后一个切片由于流未关闭,这个时刻最后一个切片文件是还没保存到本地,只是可以直接读取临时文件)。合并文件完成后,删除切片文件夹,并更新数据库信息,记录该文件已经完成。
当上传一个本地已经存在的文件时,由于数据库记录了该 md5 文件是已经完成的,所以预探请求会返回全部切片数组,前端就不会再发送 upload 请求从而实现了文件秒传。即使上传的目标目录与本地已存在文件处在不同目录,在预探请求时识别到时,也会进行复制操作,前端也不需要再传。
断点续传演示
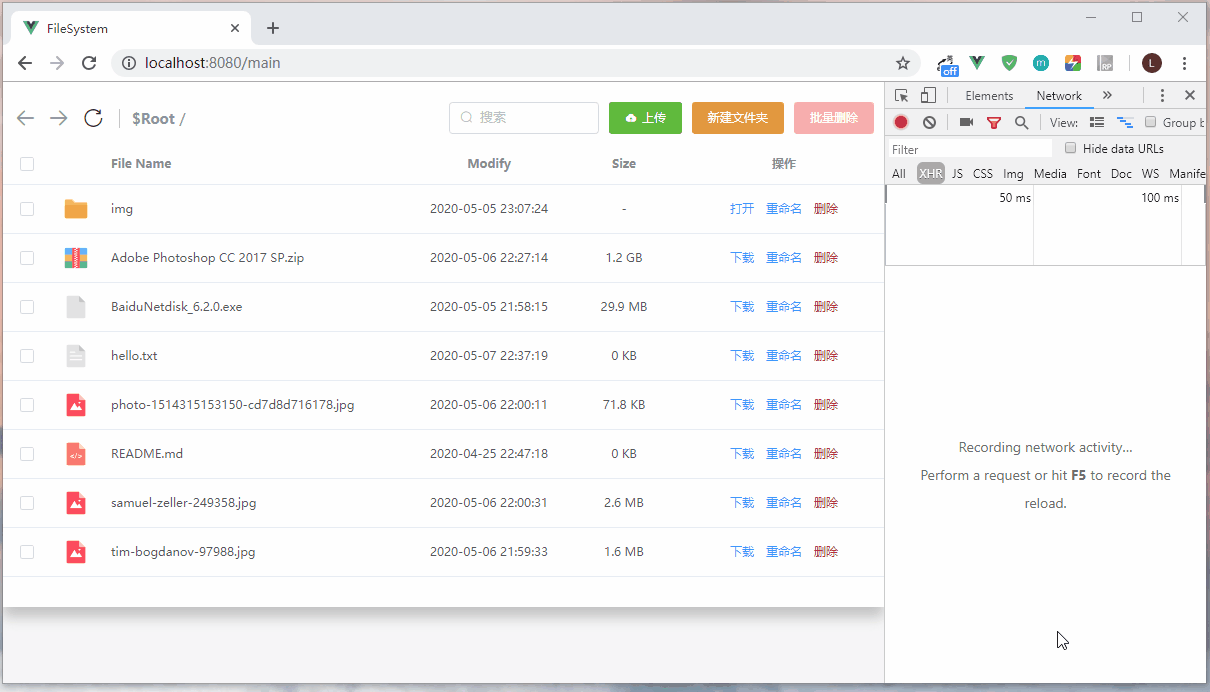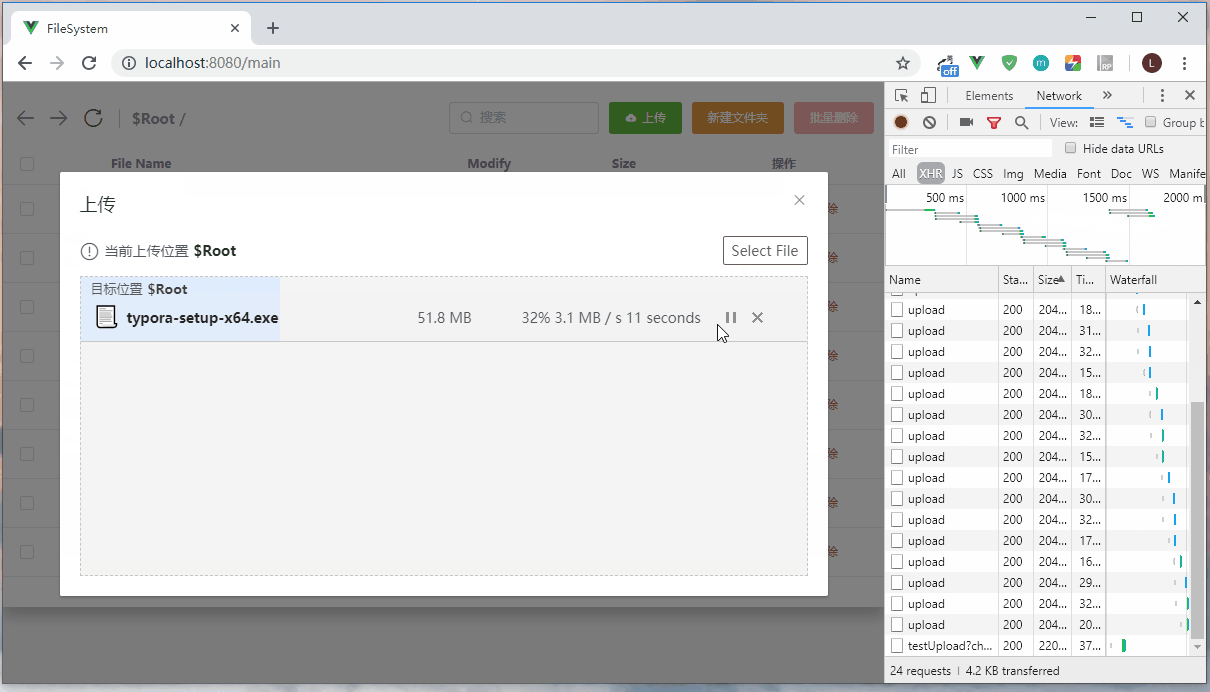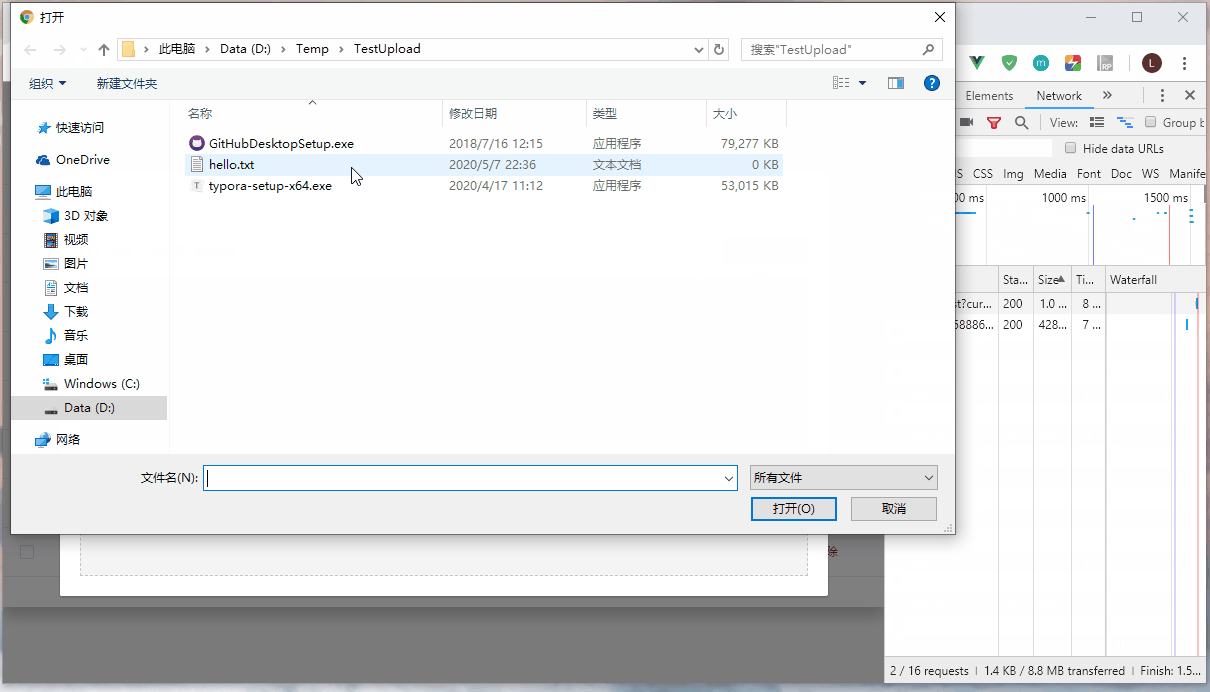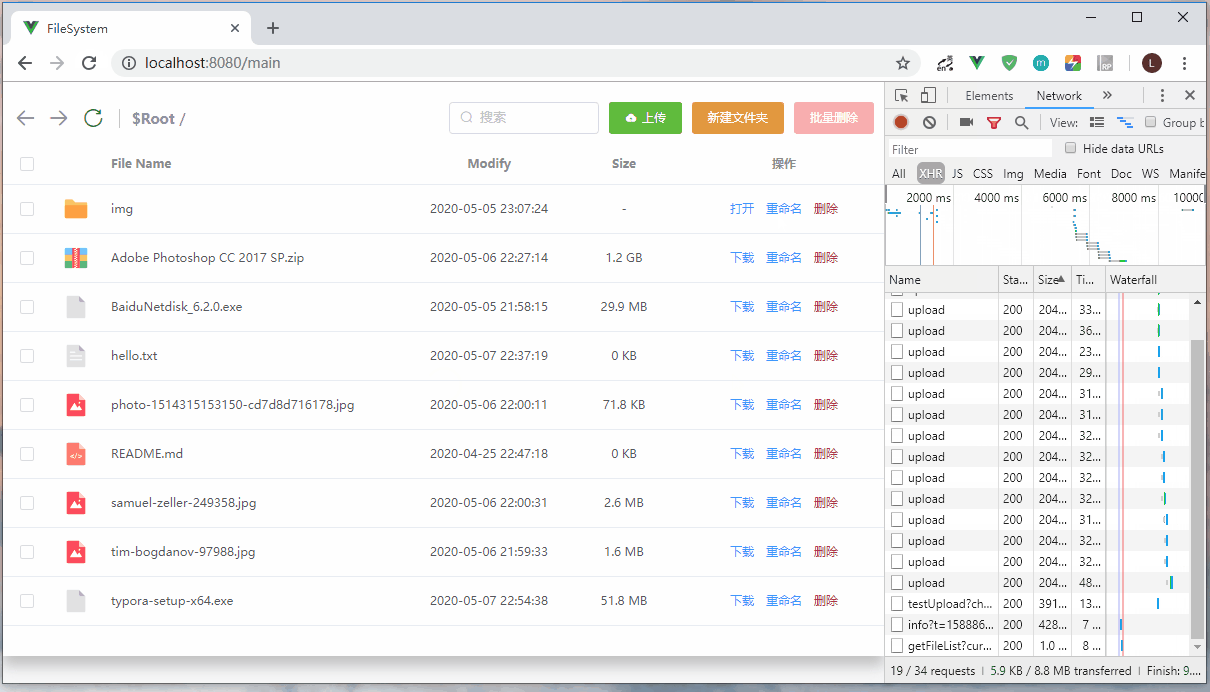
上传过程暂停,然后刷新页面,重新上传同一个文件,可以发现文件是从上传暂停的地方重新开始。
文件秒传演示

上传上面演示的同一个文件,由于发现是已经存在的文件,则会直接返回成功。
至此,一个断点续传、秒传功能的前后端都实现完了。
另外该系统还有一些对文件进行移动、删除、下载的功能都是比较简单的,基本都是使用 nodejs 的 fs 模块就能实现,这里就不细说了。
该系统前端 Git: https://github.com/leon-kfd/FileSystem
由于目前该后端是嵌入到了本人的其他系统里面,还未能开源,等有空会整理出一份。同时系统部分功能由于时间问题也还没有空去完善,望见谅。